
scala语言基础
1 |
大数据scala
一、介绍以及开发工具
运行在 JVM 上的多范式编程语言,同时支持面向对象和面向函数编程。
在线编辑器:https://scalafiddle.io/
从官网下载scala的安装程序直接安装
基于IDEA按照对应的scala插件
二、基础语法
1)、声明变量
1 | 1. val 使用val修饰的变量相当于java用final修饰的变量,它是不可以改变。 |
scala中在声明变量的时候,可以不给出变量的类型,可以通过scala编译器帮我们进行类型推断,这点和java不同,java需要强制给出类型。
scala和java的对比
| java声明变量 | scala声明变量 |
|---|---|
| String a = “123”; | var a = “123” |
| var a:String = “123” |
字符串操作
1 | 1. 和 java 相同的基础字符串 |
惰性赋值
当我们有些变量保存了超级多的数据的是,加载到 JVM 里面会有很大的内存开销,场景中数据不需要马上加载到JVM内存中,则可以使用惰性赋值提高效率。
被lazy修饰的变量初始化的时机是在第一次使用此变量的时候才会赋值,并且仅在第一次调用时计算值,即值只会被计算一次,赋值一次,再之后不会被更改了,所以lazy修饰的变量必须同时是 val 修饰的不可变变量。
1 | 语法格式: |
2)、八种基本数据类型
八种基本数据类型和java是一样的。有些地方和java有区别
- Scala中都是以大写字母开头
- 整形使用的是 Int 而不是 Integer。
- Scala 中定义变量可以不写类型,让Scala 自动推断。
- Scala中默认的整型是Int, 默认的浮点型是: Double
| 类型 | 长度 | 字节数量 |
|---|---|---|
| Boolean | 未规定 | |
| Byte | 8 | 1字节 |
| Char | 16 | 2字节 |
| Short | 32 | 2字节 |
| Int | 64 | 4字节 |
| Long | 32 | 8字节 |
| Float | 64 | 4字节 |
| Double | 64 | 8字节 |
强制自动类型转换
当Scala程序在进行运算或者赋值动作时, 范围小的数据类型值会自动转换为范围大的数据类型值, 然后再进行计算.例如: 1 + 1.1的运算结果就是一个Double类型的2.1. 而有些时候, 我们会涉及到一些类似于”四舍五入”的动作, 要把一个小数转换成整数再来计算. 这些内容就是Scala中的类型转换.
Scala中的类型转换分为
值类型的类型转换和引用类型的类型转换, 这里我们先重点介绍:值类型的类型转换.值类型的类型转换分为:
- 自动类型转换
- 强制类型转换
1.自动类型转换
解释
范围小的数据类型值会自动转换为范围大的数据类型值, 这个动作就叫: 自动类型转换.
自动类型转换从小到大分别为:Byte, Short, Char -> Int -> Long -> Float -> Double示例代码
1
2
3val a:Int = 3
val b:Double = 3 + 2.21 //因为是int类型和double类型的值进行计算, 所以最终结果为: Double类型
val c:Byte = a + 1 //这样写会报错, 因为最终计算结果是Int类型的数据, 将其赋值Byte类型肯定不行.
2.强制类型转换
解释
范围大的数据类型值通过一定的格式(强制转换函数)可以将其转换成范围小的数据类型值, 这个动作就叫: 强制类型转换.
注意: 使用强制类型转换的时候可能会造成精度缺失问题!格式
1 | val/var 变量名:数据类型 = 具体的值.toXxx //Xxx表示你要转换到的数据类型 |
- 参考代码
1 | val a:Double = 5.21 |
3.值类型和String类型之间的相互转换
1. 值类型的数据转换成String类型
格式一:
1 | val/var 变量名:String = 值类型数据 + "" |
格式二:
1 | val/var 变量名:String = 值类型数据.toString |
示例
将Int, Double, Boolean类型的数据转换成其对应的字符串形式.
参考代码:
1 | val a1:Int = 10 |
2. String类型的数据转换成其对应的值类型
格式:
1 | val/var 变量名:值类型 = 字符串值.toXxx //Xxx表示你要转换到的数据类型 |
注意:
- String类型的数据转成Char类型的数据, 方式有点特殊, 并不是调用toChar, 而是toCharArray
- 这点目前先了解即可, 后续我们详细解释
需求:
将字符串类型的整数, 浮点数, 布尔数据转成其对应的值类型数据.
参考代码:
1 | val s1:String = "100" |
3)、运算符
| 类别 | 操作运算符 |
|---|---|
| 算术运算符 | +、-、*、/ |
| 关系运算法 | >、<、==、!=、>=、<= |
| 逻辑运行 | &&、||、| |
| 位运算 | &、||、^、<<、>> |
注意:
Scala中是没有++, –这两个算术运算符的, 这点和Java中不同.
整数相除的结果, 还是整数. 如果想获取到小数, 则必须有浮点型数据参与.
例如: 10 / 3 结果是3 10 / 3.0 结果是: 3.3333(无限循环)关于+号拼接字符串: 任意类型的数据和字符串拼接, 结果都将是一个新的字符串.
关于%操作, 假设求
a % b的值, 它的底层原理其实是:a - a/b * b与java不同,在scala中,可以直接使用 ==、!=进行比较,与java中调用 equals 方法是一致的。而比较两个对象的引用值,使用 eq。
赋值运算符
1 | //将常量值1赋值给变量a |
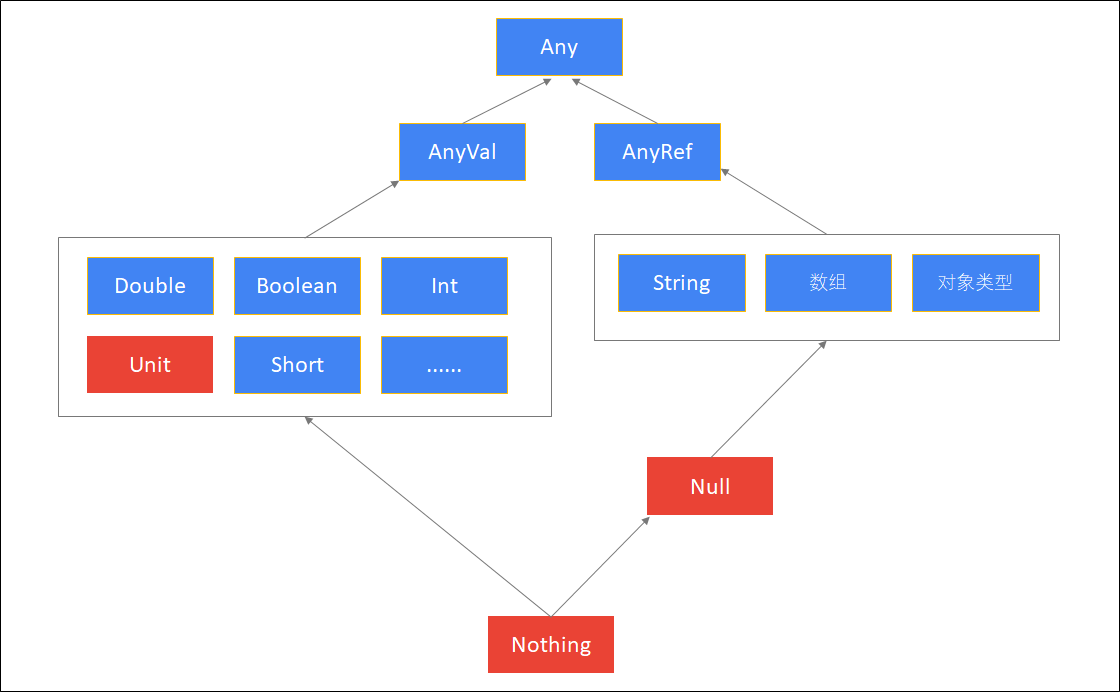
4)、Scala类型层次结构
单根集成结构,所有Scala类型都是从Any类型继承,AnyVla 是所有值类型的父类,而 AnyRef 是所有引用类型的父类。
| 类型 | 说明 |
|---|---|
| Any | 所有类型的父类,它有两个子类AnyRef与AnyVal |
| AnyVal | 所有数值类型的父类 |
| AnyRef | 所有对象类型(引用类型)的父类 |
| Unit | 表示空,Unit是AnyVal的子类,它只有一个的实例**()**它类似于Java中的void,但scala要比Java更加面向对象。 |
| Null | Null是AnyRef的子类,也就是说它是所有引用类型的子类。它的实例是null 可以将null赋值给任何对象类型 |
| Nothing | 所有类型的子类, 不能直接创建该类型实例,某个方法抛出异常时,返回的就是Nothing类型,因为Nothing是所有类的子类,那么它可以赋值为任何类型 |
5)、IF语句
和java类似,但是是有返回值的。
而且 Scala 中没有三元表达式,可以直接使用 if 表达式替代。
1 | val a=1 |
java中的写法
1 | int a = 1; |
6)、块表达式
就是我们在声明一个变量的时候,后面跟上{},大括号中有很多个表达式,其中最后一个表达式的值就是块的值。
1 | val a=1 |
7)、for循环
和java区别比较大
1 | for(变量 <- 集合/数组/表达式) |
样例
1 | 1.样例一打印99乘法表 |
1 to 10 对应的是 i=1;i<=10;i++,开头的1和结尾的10都可以取到
| scala | java | |
|---|---|---|
| for(i <- 1 to 10) println(i) | for(i =1;i<=10;i++) println(i) | |
| for(i <- 1 to 9;j <- 1 to i) 嵌套写法 | ||
| yield 返回一个新的集合 |
8)、while循环
1 | 1.样例 |
9)、break和continue使用
scala 循环中想用break和continue比较麻烦,需要先导入包,再使用。
使用break的时候需要用breakable{}把整个循环体包裹起来。
1 | import scala.util.control.Breaks._ |
使用continue的时候需要breakable{}把for表达式包裹起来,里面没有continue关键词,用的还是break()
1 | for( i <- 1 to 50 ) |
三、方法和函数
方法用的少,函数用的多
1)、方法,def
- 定义方法,关键字 def
- 方法的返回值类型可以不写,编译器可以自动推断出来,但是对于递归函数,必须指定返回类型
- 定义方法的时候,可以给方法的参数指定一个默认值。
- 变长参数,参数个数不定,定义的时候使用*定义
1 | def m1(x:Int,y:Int):Int=x+y |
方法的调用方式
后缀调用法
1
2对象名.方法名(参数)
scala> Math.abs(-1)中缀调用法
1
2
3
4对象名 方法名称 参数
scala> 1 to 10
scala> Math abs -1花括号调用法
1
2scala> Math.abs{ -1 }
scala> Math.abs{ println("求绝对值") ;-1 }括号里面只有一个参数的是,才可以用花括号调用法。
本质是把花括号当做块表达式,把块表达式返回的值当做参数。
无括号调用法
1
2
3
4如果目标方法不需要参数,则调用的时候不用写括号,可以直接调用。
def m3()=println("hello")
def m3() {println("hello"}
m3()
2)、函数
函数相比方法的特殊之处在于,函数是一个对象。在函数式编程语言中,函数是头等公民,它可以像任何其他数据类型一样被传递和操作,函数是一个对象,继承自FuctionN。函数对象有apply、curried、toString、tupled这些方法。而方法不具有这些特性。
函数的声明和调用
1
2
3
4
5val 函数名称 = (参数名:参数类型,参数名:参数类型......) => 函数体
val f1=(x:Int,y:Int) => x+y
var a = f1(1,2)将方法转换成函数的
使用方法名+下划线转换成函数
1
val f1=m1 _
函数和方法的区别
函数:
- 函数在scala中它是一个对象,具有该对象中的一些方法
- 当前这个函数有N个输入参数,该函数就继承自FunctionN类
- 可以将函数对象赋值给一个变量,在运行的时候是加载到 JVM 的堆内存中。
方法:
- 方法就是对象中的方法,它是不具备函数这种特性。
- 方法是隶属于类或者对象的,运行的时候,他是加载到 JVM 的方法区的。
四、数据结构-数组Array
一、定长数组
定长数组的定在于长度不可变,但是其中的值是可以变化的。
对应的类型是Class[_ <: Array[Int]] = class [I
定义定长数组的办法
1
2
3
4val array=Array(5) // 只定义一个长度,所有元素均为0
val array=Array[Int](5) // 可以加上类型,所有元素均为0
val array=new Array[Int](5) // 还可以加上new关键字
val array=Array(1,2,3,4,5) // 直接初始化一些值进去java 定义数组的方法:
1
2
3String [] sarr = new String [6];
String [] sarr = new String []{"a","b","c","d"};
String [] sarr = {"a","b","c","d"};java中的数组是一种类型,scala中的数组的一个对象,是Array对象,创建一个Array对象就是创建一个数组。
打印数组内容
1
2
3
4
5println(array) // 打印的是内存地址
println(array.toString) // 打印的是内存地址
// 将数组转换成数组缓冲,就可以看到原数组中的内容了
println(array.toBuffer) // 打印的是数组数据访问数组内容
1
2访问数组内容,从0开始
println(array(2))java 访问数组内容
1
2String [] sarr = {"a","b","c","d"};
sarr[0]和scala还是有区别的,一个是小括号调用方法,一个是方括号取数组指定元素修改内容
1
array(0) = 100
二、变长数组
需要导入包:import scala.collection.mutable.ArrayBuffer
定义数组
和定长是一样的,类型要从Array变成ArrayBuffer
打印数组
打印数组内容,和定长有区别,不再打印内存地址,三种输出的都是数据
1
2
3println(array) // 打印的是数组数据
println(array.toString) // 打印的是数组数据
println(array.toBuffer) // 打印的是数组数据添加元素操作
1
2
3
4
5
6array +=1
array += (2,3,4) // 插入一个元组
array ++= Array(5,6) // ++= 用于右侧是一个数组对象
array ++= ArrayBuffer(7,8) // ++= 用于右侧是一个数组对象
array.insert(0,9) //在数组某个位置插入元素用insert,从某下标插入,原来0位置的元素会被后移
array.insert(0,1,2,3,4,5) //在数组某个位置插入元素用insert,从某下标插入,一次插入多个元素如果初始化数组的是没有初始化值,也没有初始化类型,则可能会导致无法插入数据,初始化的时候无参则需要配置类型。
1
2
3
4
5
6
7
8
9scala> var array = ArrayBuffer()
scala> array.append(4)
^
error: type mismatch;
found : Int(4)
required: Nothing
scala> var array = ArrayBuffer[Int]() // 创建的时候带上类型
scala> array.append(4) // 正常插入按照值删除元素操作
按照值删除元素,从数据中删除值相同的元素,如果有多个值相同的元素,则从左边开始删除第一个。
1
2
3
4array -=100
array -=(2,3,4)
array --=Array(5,6)
array --=ArrayBuffer(7,8)按照下标删除元素操作
1
array.remove(0)
支持的符号操作
符号 含义 + += ++=
三、循环数组
1 | 1. 直接使用for循环获取每一个元素 |
四、迭代循环样例算法
1 | 各种写法的迭代: |
五、yield关键字用法
1 | yield关键字将原始的数组进行转换会产生一个新的数组,原始的数组不变 |
六、常用算法
1 | arr.sun 求和 |
五、数据结构-映射Map
一、不可变Map
构建
默认的map是不可变的map,是属于immutable包下的Mpa
1
2
3
4
5
6
71. 使用建值基本方法
val map=Map("键" -> "值" ,"键" -> "值")
val map=Map("zhangsan" -> 30,"lisi" -> 40)
2. 使用元祖
val map=Map(("键","值"),("键","值"))
val map1=Map(("zhangsan",30),("lisi",40))java 构建map的方法
1
Map map = new HashMap<String,String>();
获取值
1
2
3
41. 值=map(键)
2. map.getOrElse(键,默认值)
如果key存在就获取真实的值,如果不存在就给一个默认值,避免在不确定map中是否存在这个key的情况下报错值=map(键) 如果键不存在则会报错,为了避免报错可以用getOrElse
二、可变Map
引入包:import scala.collection.mutable.HashMap
定义
1
2
3
4定义可变Map,同定长一样,但是Map类型要修改为HashMap类型
val hmap=HashMap("zhangsan" -> 30,"lisi" -> 40)
val hmap=HashMap("zhangsan" -> 30,"lisi" -> 40)获取值,同定长一样
添加元素
1
2hmap +=("lisi" -> 60,"wangwu" ->40)
hmap.put("zhaoliu",50)修改元素
1
2hmap("lisi")=70
hmap +=("lisi" -> 80)删除元素
1
2hmap -=("lisi")
hmap.remove("wangwu")显示所有元素
1
2map.keys.foreach(println(_))
map.keySet.foreach(println(_))遍历元素
1
2
3
4
5
6
7
8a. 先得到key,循环key获取val
for(x<- map.keys) println(x+" -> "+map(x))
b. for循环,模式匹配,得到KV
for((x,y) <- map) println(x+" -> "+y)
c. 使用map.foreach循环得到kv
map.foreach{case (x,y) => println(x+" -> "+y)}
六、数据结构元祖
映射是K/V对偶的集合,对偶是元组的最简单形式,元组可以装着多个不同类型的值,元素不是set,里面的值是有顺序的。元组构建完成之后,里面的值是不允许修改,而且里面的值是有先后顺序的。
- 构建元素
(1)元组是不同类型的值的聚集;对偶是最简单的元组。
(2)元组表示通过将不同的值用小括号括起来,即表示元组。
1 | val/var 元组 = (元素1,元素2,元素3......) //一般的定义方法 |
获取元祖的值
1
2
3获取元组中的值格式:
使用下划线加脚标 ,例如 t._1 t._2 t._3
注意:元组中的元素脚标是从1开始的循环获取元素内容
1
2
3val t = (4,3,2,1)
t.productIterator.foreach{ i =>println("Value = " + i )}
println(t._1) // 打印第一个元素操作1,将对偶的集合转成映射
1
2
3
4val arr = Array( ("tom",88),("jerry",95) )
val map = arr.toMap
println(map)
immutable.Map[String,Int] = Map(tom -> 88, jerry -> 95)操作2,数据的拉链操作,zip函数
1
2
3
4val names = Array("tom","jerry","xa")
val score = Array(88,95,100)
val z = names.zip(score)
z: Array[(String, Int)] = Array((tom,88), (jerry,95), (xa,100))
七、集合-列表list
在Scala中列表要么为空(Nil表示空列表)要么是一个head元素加上一个tail列表。
9 :: List(5, 2) :: 操作符是将给定的头和尾创建一个新的列表
注意::: 操作符是右结合的,如9 :: 5 :: 2 :: Nil相当于 9 :: (5 :: (2 :: Nil))
一、基础操作
默认的定长集合
1
2
3
4immutable 包中的
val list=List(1,2,3,4)
val list=Nil // 创建一个不可变的空列表
val list=元素1 :: 元素2 :: ... :: Nil //创建一个不可变列表,最后必须是Nil结束可变集合
1
2
3
4import scala.collection.mutable.ListBuffer
val list=ListBuffer(1)
val list = new ListBuffer()
val list = new ListBuffer[Int]()可变集合添加元素
1
2
3
4
5
6
7
8list +=2
list.append(3)
list ++= List(4,5)
list ++= ListBuffer(6,7)
var a = List(1,2,3)
var b = List(4,5,6)
var c = a++b可变集合删除元素
1
2
3
4list -=2 //按照值删除元素
list.remove(0) //按照下标删除元素
list --=List(4,5) //删除存在于另外一个集合中的值
list --=ListBuffer(6,7) //同上常用操作符,对于定长集合,所有操作都会返回一个新的集合
在集合头部插入一个元素
1
2
3
4
5
6
7
8+: (elem: A): List[A] 在列表的头部添加一个元素
:: (x: A): List[A] 在列表的头部添加一个元素
val lst2 = 0 :: lst1
val lst3 = lst1.::(0)
val lst4 = 0 +: lst1
val lst5 = lst1.+:(0)在列表尾部插入一个元素或者另外一个列表
1
2
3
4
5
6
7
8
9
10
11:+ (elem: A): List[A] 在列表的尾部添加一个元素
++ [B](that: GenTraversableOnce[B]): List[B] 从列表的尾部添加另外一个列表
val lst6 = lst1 :+ 3 // 在末尾添加一个元素
val lst0 = List(4,5,6)
val lst7 = lst1 ++ lst0 // ++ ++: 两种相同
val lst7 = lst1 ++: lst0
// 下面两种等价
left ++ right // List(1,2,3,4,5,6)
right.:::(left) // List(1,2,3,4,5,6)常用方法
1
2
3
4
5scala> val a = List(1,2,3)
val a: List[Int] = List(1, 2, 3)
scala> a.isEmpty
val res5: Boolean = false获取首个元素和剩余部分
1
2
3val a = List(1,2,3)
a.head // 获取首个元素
a.tail // 获取首个元素以外的元素翻转列表
1
2val = List(1,2,3)
a = a.reverse // 返回翻转后的元素获取前缀后缀
1
2
3val a = List(1,2,3,4,5) // 获取前三个元素
a.take(3) // 获取前三个元素
a.drop(3) // 除了前三个以外的元素全要扁平化操作
列表里面嵌套列表的结构,List( List(1,2,3),List(4,5,6) )拍平放到一个列表里面。
注意如果List里面嵌套既有元素,又有集合例如[1,2,3,[a,b,c,b]],会报错无法拍平。
1
2
3
4
5
6
7
8
9
10
11
12// 正确示例
scala> val a = List( List(1,2,3),List(4,5,6) )
scala> a.flatten
val res12: List[Int] = List(1, 2, 3, 4, 5, 6)
// 错误示例
scala> val a = List( List(1,2,3),List(4,5,6),7,8,9 )
val a: List[Any] = List(List(1, 2, 3), List(4, 5, 6), 7, 8, 9)
scala> a.flatten
^
error: No implicit view available from Any => scala.collection.IterableOnce[B].拉链和拉开
拉链操作:使用zip将两个列表,组合成一个元素为元组的列表
拉开操作:讲一个包含元组的列表,解开成包含两个列表的元组
示例:
有两个列表,第一个列表是学生姓名列表[zhangsan,lisi,wangwu],第二个列表是学生年龄列表[12,14,16]将两个列表组合在一起,变成[ (zhangsan->12),(lisi->14),(wangwu->16) ],这个操作即为拉链操作,反之为拉开操作。
1
2
3
4
5
6
7
8
9
10// 拉链操作
val namelist = List("张三","李四","王五")
val agelist = List(12,15,14)
val c = namelist.zip(agelist)
val c: List[(String, Int)] = List((张三,12), (李四,15), (王五,14))
// 拉开操作
scala> val d = c.unzip
val d: (List[String], List[Int]) = (List(张三, 李四, 王五),List(12, 15, 14))字符串生成
toString()操作,返回list中的所有元素
1
2
3
4
5
6
7
8
9
10val a = List(1,2,3)
print(a.toString) // 转换字符串
输出结果:List(1, 2, 3) // 默认输出格式
print(a.mkStrin) // 指定字符串分割,不传参即为无分隔符
输出结果:123
print(a.mkStrin(":")) // 已冒号为分隔符
输出结果:1:2:3并集合
1
2
3
4
5
6
7
8
9
10val a = List(1,2,3,4)
val b = List(3,4,5,6)
// 取并集,不会去重,已经被废弃,可以改用concat
val c = a.union(b)
返回的新集合:List(1, 2, 3, 4, 3, 4, 5, 6)
// 使用 distinct 对上面的集合 c 进行去重
val d = c.distinct
返回的新集合:List(1, 2, 3, 4, 5, 6)交集
1
2
3
4
5
6val a = List(1,2,3,4)
val b = List(3,4,5,6)
// 取交集,会做去重处理
val c = a.intersect(b)
返回的新集合:List(3, 4)差集
1
2
3
4
5
6
7
8
9
10val a = List(1,2,3,4)
val b = List(3,4,5,6)
// 差集,a中有,b中没有的元素,而且如果a中有重复元素,则差集中也会有
val c = a.diff(b)
返回的新集合:List(1, 2)
val a = List(1,2,3,4,4,4)
val b = List(3,4,5,6)
a.diff(b) // 输出List(1, 2, 4, 4)
二、变长集合常用操作
1 | //构建一个可变列表,初始有3个元素1,2,3 |
八、集合-set
特点:Set代表一个没有重复元素的集合;将重复元素加入Set是没有用的,而且 Set 是不保证插入顺序的,即 Set 中的元素是乱序的。
一、定义不可变set,以及常见操作
定义
1
2
3
4
5
6定义:val set=Set(元素,元素,.....)
val/var 变量名 = Set[类型]() // 定义空集合
val/var 变量名 = Set[类型](v1,v2,v3) // 初始化元素
val set =Set(1,2,3,4,5,6,7)
set: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 7, 3, 4)常用函数
1
2
3
4
5
6
7
8
9
10
111.元素个数
scala> set.size
res0: Int = 7
2.取集合最小值
scala> set.min
res1: Int = 1
3.取集合最大值
scala> set.max
res2: Int = 7set集合新增删除元素,生成一个新的set
1
2
3
4
5
6
7
8将元素和set1合并生成一个新的set,原有set不变
scala> set + 8
res3: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 7, 3, 8, 4)
scala> set - 8
res4: scala.collection.immutable.Set[Int] = Set(5, 1, 6, 2, 7, 3, 4)拼接两个set,生成一个新的set
1
2
3
4
5val a = Set(1,2,3,4,5)
val b = Set(6,7,8,9,10)
val c = a ++ b
val c: scala.collection.mutable.Set[Int] = HashSet(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)拼接集合和列表,生成一个新的set
循环获取set元素
1
2
3
4val a = Set(1,2,3,4,5)
for( i <- a ){
println(i)
}
1 | 6. 两个集合的交集 |
二、可变set集合
1 | 1. 导入包 |
九、迭代器
- 使用 iterator 方法可以从集合获取一个迭代器
- 迭代器的两个基本操作
- hasNext 查询容器中是否有下一个元素
- next 返回迭代器的下一个元素,如果没有则抛出NoSuchElementException
- 每一个迭代器都是有状态的
- 迭代完后保留最后一个元素的位置
- 再起使用抛出NoSuchElementException
- 可以使用while或者for来逐个返回元素
1 | val a = List(1,2,3,4) |
十、函数式编程
1)、遍历foreach
方法签名
1 | foreach(f: (A) => Unit): Unit |
样例
1 | val a = List(1,2,3,4) |
2)、映射map
集合映射操作是将一个数据类型转换成另外一个数据类型的过程。
map方法接受一个函数,将这个函数应用到每一个元素,返回一个新的列表。
方法签名:
1 | def map[B](f: (A) => B): TraversableOnce[B] |
数据样例:
1 | val a = List(1,2,3,4) |
3)、扁平化映射 flatMap
映射map的局限性在于,里面的函数对象只能返回一个值,而flatMap中调用的函数对象则可以返回一个集合,然后会自动将大的集合flatten拍平。
方法签名:
1 | def flatMap[B](f:(A) => GenTraversableOnce[B]): TraversableOnce[B] |
样例:
- 需求:有一个包含若干个文本行的列表,每一个由多个空格分割的单词组成,需要提取每个单词。
1 | val s = List("hadoop hive spark flink","kudu hbase sqoop storm") |
4)、过滤 filter
接受一个类型,调用函数,函数会返回一个true,false,为false的会被过滤掉。
方法签名:
1 | def filter(p: (A) => Boolean): TraversableOnce[A] |
样例:
1 | val a = List(1,2,3,4,5,6,7,8) |
5)、排序 sortBy,根据指定字段排序
方法签名
1 | def sortBy[B](f: (A) => B): List[A] |
示例
- 有一个列表,分别包含以下几个文本行”01 hadoop”,”02 flume”,”03 hive”,”04 spark”
- 安装单词字母进行排序
1 | val a = List("01 hadoop","02 flume","03 hive","04 spark") |
6)、排序 sortWith,自定义排序
方法体:
1 | def softWith(lt: (A,A) => Boolean):List[A] |
样例:
1 | val a = List(5,3,6,3,45,9,12) |
7)、分组 groupBy
方法体:
1 | def groupBy[K](f:(A) => k):Map[K,List[A]] |
样例数据
有一个列表,包括学生姓名和性别,按照学生的性别进行分组
1
2
3张三 男
李四 女
王五 男
1 | val a = List(("张三"->"男"),("李四"->"女"),("王五"->"男")); |
8)、聚合函数reduce | fold
将一个列表或者集合进行聚合吗,滚动调用函数,每次传入上一次执行后的结果。
方法签名:
1 | def reduce[A1 >: A](op: (A1, A2) => A1):A1 |
样例数据:
1 | val a = List(1,2,3,4) |
reduce和reduceLet效果是一样的,表示从左往右计算
reduceRight 表示从右往左计算
方法签名
1 | def fold[A1 >: A](z: A1)(op: (A1, A2) => A1):A1 |
样例数据:
1 | val a = List(1,2,3,4) |
fold和foldLet效果是一样的,表示从左往右计算
foldRight 表示从右往左计算
fold和reduce的区别是,fold调用的是需要传递一个初始化参数,而reduce不用。