
spark基础
Spark基础
第1章 Spark 概述
1.1 Spark 是什么
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
1.2 Spark and Hadoop
在之前的学习中,Hadoop 的 MapReduce 是大家广为熟知的计算框架,那为什么咱们还 要学习新的计算框架 Spark 呢,这里就不得不提到 Spark 和 Hadoop 的关系。
从功能上看区分:
hadoop
- Hadoop 是由 java 语言编写的,在分布式服务器集群上存储海量数据并运行分布式 分析应用的开源框架
- 作为 Hadoop 分布式文件系统,HDFS 处于 Hadoop 生态圈的最下层,存储着所有 的 数 据 , 支 持 着 Hadoop 的 所 有 服 务 。 它 的 理 论 基 础 源 于 Google 的 TheGoogleFileSystem 这篇论文,它是 GFS 的开源实现。
- MapReduce 是一种编程模型,Hadoop 根据 Google 的 MapReduce 论文将其实现, 作为 Hadoop 的分布式计算模型,是 Hadoop 的核心。基于这个框架,分布式并行 程序的编写变得异常简单。综合了 HDFS 的分布式存储和 MapReduce 的分布式计 算,Hadoop 在处理海量数据时,性能横向扩展变得非常容易。
- HBase 是对 Google 的 Bigtable 的开源实现,但又和 Bigtable 存在许多不同之处。 HBase 是一个基于 HDFS 的分布式数据库,擅长实时地随机读/写超大规模数据集。 它也是 Hadoop 非常重要的组件。
spark
- Spark 是一种由 Scala 语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core 中提供了 Spark 最基础与最核心的功能
- Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
- Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的 处理数据流的 API。
1.3 Spark or Hadoop
Hadoop 的 MR 框架和 Spark 框架都是数据处理框架,那么我们在使用时如何选择呢?
- Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多 并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存 在诸多计算效率等问题。所以 Spark 应运而生,Spark 就是在传统的 MapReduce 计算框 架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速 度,并将计算单元缩小到更适合并行计算和重复使用的 RDD 计算模型。
- 机器学习中 ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据 反复查询反复操作。MR 这种模式不太合适,即使多 MR 串行处理,性能和时间也是一 个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。而 Spark 所基于的 scala 语言恰恰擅长函数的处理。
- Spark 是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient Distributed Datasets),提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集 进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。
- Spark 和Hadoop 的根本差异是多个作业之间的数据通信问题 : Spark 多个作业之间数据 通信是基于内存,而 Hadoop 是基于磁盘。
- Spark Task 的启动时间快。Spark 采用 fork 线程的方式,而 Hadoop 采用创建新的进程 的方式。
- Spark 只有在 shuffle 的时候将数据写入磁盘,而 Hadoop 中多个 MR 作业之间的数据交 互都要依赖于磁盘交互
- Spark 的缓存机制比 HDFS 的缓存机制高效。
经过上面的比较,我们可以看出在绝大多数的数据计算场景中,Spark 确实会比 MapReduce 更有优势。但是 Spark 是基于内存的,所以在实际的生产环境中,由于内存的限制,可能会 由于内存资源不够导致 Job 执行失败,此时,MapReduce 其实是一个更好的选择,所以 Spark 并不能完全替代 MR。
1.4 Spark 核心模块

Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark 其他的功能如:Spark SQL, Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的。
Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过 Spark SQL,用户可以使用 SQL 或者 Apache Hive 版本的 SQL 方言(HQL)来查询数据。
Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理 数据流的 API。
Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib 不仅提供了模型评估、数据导入等 额外的功能,还提供了一些更底层的机器学习原语。
Spark GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
第2章 Spark 高可以环境搭建
第一个坑,java环境有问题,重装一遍就好。
spark在的本地快速启动不需要hadoop等环境,第一次在linux上执行./bin/spark-shell报了一个缺少no jaas_unix in java.library.path的错误,后来发现是JAVA JDK的问题,另外一台机器上的java8就没问题,这台机器上的就有问题,随后又重新下载了一个java 9 直接搞定,就没问题呢了。
尚硅谷HA搭建步骤:
启动所有zookeeper服务。
进入解压缩后路径的 conf 目录,修改 slaves.template 文件名为 slaves
1
mv slaves.template slaves
修改 slaves 文件,添加 work 节点
1
2
3hadoop1
hadoop2
hadoop3修改 spark-env.sh.template 文件名为 spark-env.sh
1
mv spark-env.sh.template spark-env.sh
修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点
1
2
3
4
5
6
7
8export JAVA_HOME=/opt/module/jdk1.8.0_144
#Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989,也可以自定义,访问 UI 监控页面时请注意
SPARK_MASTER_WEBUI_PORT=8989
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=linux1,linux2,linux3
-Dspark.deploy.zookeeper.dir=/spark"修改spark-env.sh文件,添加hadoop配置文件路径
1
2
3## HADOOP软件配置文件目录,读取HDFS上文件和运行Spark在YARN集群时需要,先提前配上
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop主节点启动当前机器的master和所有Worker节点
1
${SPARK_HOME}/sbin/start-all.sh
备用节点启动master服务
1
${SPARK_HOME}/sbin/start-master.sh
配置历史服务
由于 spark-shell 停止掉后,集群监控 linux1:4040 页面就看不到历史任务的运行情况,所以 开发时都配置历史服务器记录任务运行情况。
修改 spark-defaults.conf.template 文件名为 spark-defaults.conf
1
mv spark-defaults.conf.template spark-defaults.conf
修改spark-default.conf 文件,配置日志存储路径
1
2spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop1:8020/directory此处有一个坑,就是里面的8020端口,这个是hadoop3里面,dfs的端口默认是8020,用于访问文件系统,但是我在dfs的配置文件中core-site.xml配置了fs.defaultFS的值为9000,所以访问dfs文件系统的时候,需要把上面的8020改成9000端口才可以。
注意:需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在。
1
2sbin/start-dfs.sh
hadoop fs -mkdir /directory修改 spark-env.sh 文件, 添加日志配置
- 参数 1 含义:WEB UI 访问的端口号为 18080
- 参数 2 含义:指定历史服务器日志存储路径
- 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序 信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
1
2
3
4export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop:9000/directory
-Dspark.history.retainedApplications=30"注意上面的9000端口是自己修改后的dfs文件系统的端口。
分发配置文件以及启动历史服务
1
2sbin/start-all.sh
sbin/start-history-server.sh
测试服务器
测试的步骤按照黑马的进行测试。
准备文件
1
2
3
4
5
6
7vim /root/words.txt
内容如下:
hello me you her
hello me you
hello me
hello把文件发送到dfs上
1
2hadoop fs -mkdir -p /wordcount/input
hadoop fs -put /root/words.txt /wordcount/input/words.txt登录到spark
1
/opt/module/spark/bin/spark-shell --master spark://hadoop1:7077,hadoop2:7077
在spark中执行命令,进行文件的MR操作
1
2
3
4val textFile = sc.textFile("hdfs://hadoop1:9000/wordcount/input/words.txt")
val counts = textFile.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
counts.collect
counts.saveAsTextFile("hdfs://hadoop1:9000/wordcount/output47")查看结果
结果应该在hdfs上的hdfs://hadoop1:9000/wordcount/output47可以查看结果。
端口和web页面地址整理
- 内部通信地址7077
- spark: 4040 任务运行web-ui界面端口
- spark: 8080 spark集群web-ui界面端口,被SPARK_MASTER_WEBUI_PORT参数修改了。
- spark: 7077 spark提交任务时的通信端口,也是登录spark命令行使用的端口
- hadoop: 50070集群web-ui界面端口
- hadoop:8020/9000(老版本) 文件上传下载通信端口
第3章 Spark-to-yarn
为什么不使用spark集群,而是使用yarn?
- SparkOnYarn的本质是把Spark任务的class字节码文件打成jar包,上传到Yarn集群的JVM中去运行!
- Spark集群的相关角色(IVM进程)也会在Yarn的IVM中运行
- SparkOnYarn需要:
- 修改一些配置,让支持SparkOnYarn
- Spark程序打成的jar包,可以先使用示例jar包spark—examples_2.11—3.0.1.jar,也可以后续使用我们自己开发的程序打成的jar包
- Spark任务提交工具:bin/spark-submit
- Spark本身依赖的jars:在spark的安装目录的jars中有,提交任务的时候会被上传到Yarn/HDFS,或手动提前上传上.
- SparkOnYarn不需要Spark集群,只需要一个单机版spark解压包即可(有示例jar,有spark—submit,有依赖的jars)
- SparkOnYarn根据Driver运行在哪里分为2种模式:client模式和cluster模式
注意:
在实际开发中, 大数据任务都有统一的资源管理和任务调度工具来进行管理! —Yarn使用的最多!
因为它成熟稳定, 支持多种调度策略:FIFO/Capcity/Fair
可以使用Yarn调度管理MR/Hive/Spark/Flink
1).配置Yarn历史服务器并关闭资源检查
修改文件:vim ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
1 | <configuration> |
重启yarn
1 | {HADOOP_HOME}/sbin/stop-yarn.sh |
2).配置spark的历史服务器和yarn整合
进入配置目录${SPARK_HOME}/conf
spark-defaults.conf
1
2mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf添加内容
1
2
3
4
5spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop1:9000/sparklog
spark.eventLog.compress true
spark.yarn.historyServer.address hadoop3:18080
spark.yarn.jars hdfs://hadoop1:9000/spark/jars/*spark-env.sh 增加日志配置信息
1
2
3
4export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop1:9000/sparklog/
-Dspark.history.retainedApplications=30"
dfs上手动创建文件夹
hadoop fs -mkdir -p /sparklog
vim log4j.properties 修改日志级别
把
log4j.properties.template文件重命名为log4j.properties,然后需改其中的级别。1
2
3
4mv log4j.properties.template log4j.properties
#log4j.rootCategory=INFO, console
log4j.rootCategory=WARN, console
3).配置依赖的sparkjar包
在HDFS上创建存储spark相关jar包的目录
1
hadoop fs -mkdir -p /spark/jars/
上传
${SPARK_HOME}/jars所有jar包到HDFS1
hadoop fs -put /export/server/spark/jars/* /spark/jars/
在hadoop1上修改${SPARK_HOME}/conf/spark-defaults.conf
指定spark jar包在hdfs上的路径。
1
2vim /export/server/spark/conf/spark-defaults.conf
spark.yarn.jars hdfs://node1:9000/spark/jars/*
4).启动服务
启动HDFS和YARN服务,在node1执行命令
1
2
3
4start-dfs.sh
start-yarn.sh
或
start-all.sh启动MRHistoryServer服务,在 hadoop3 执行命令
1
mr-jobhistory-daemon.sh start historyserver
启动Spark HistoryServer服务,在hadoop1执行
1
/export/server/spark/sbin/start-history-server.sh
查看页面
MRHistoryServer服务WEB UI页面:
Spark HistoryServer服务WEB UI页面,查看任务运行,download下来的东西是la4

在hadoop上查看任务日志,而且还可以查看log
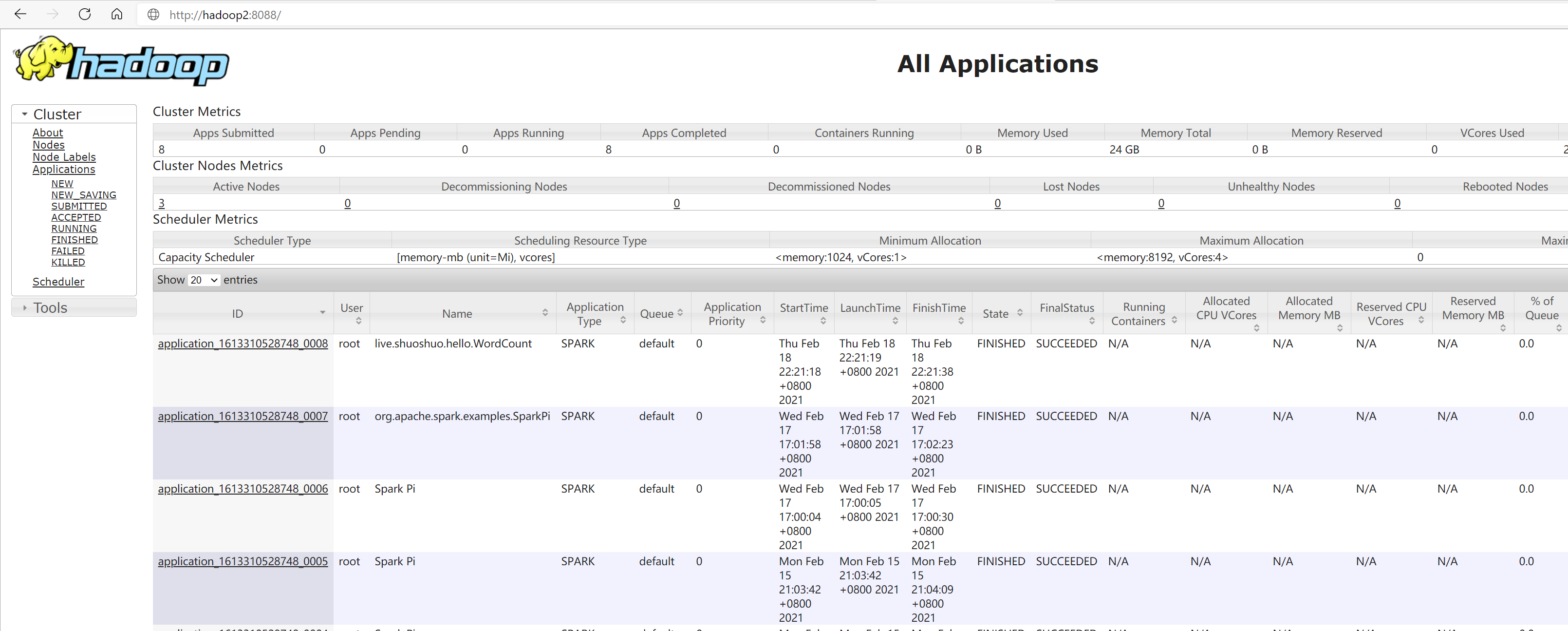
两种模式
client-了解

提交任务执行
1.client模式
1 | SPARK_HOME=/opt/module/spark |
2.cluster模式
1 | SPARK_HOME=/opt/module/spark |
spark-shell和spark-submit的区别
spark-shell命令:spark的交互式窗口,启动后直接编写spark命令,即时运行,一般在学习测试的时候使用。
spark-submit命令:用来将spark任务/程序jar包提交到spark集群,(yarn集群)。
第2章 Spark代码开发
1).本地运行
IDEA构建一般的Maven项目,引入pom.xml文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>spark_study</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<encoding>UTF-8</encoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<scala.version>2.12.11</scala.version>
<spark.version>3.0.1</spark.version>
<hadoop.version>2.7.5</hadoop.version>
</properties>
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>apache</id>
<url>https://repository.apache.org/content/repositories/snapshots/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!--依赖Scala语言-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!--SparkCore依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-streaming-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--spark-streaming+Kafka依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--SparkSQL依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--SparkSQL+ Hive依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--StructuredStreaming+Kafka依赖-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- SparkMlLib机器学习模块,里面有ALS推荐算法-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.38</version>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<plugins>
<!-- 指定编译java的插件 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.5.1</version>
</plugin>
<!-- 指定编译scala的插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<useFile>false</useFile>
<disableXmlReport>true</disableXmlReport>
<includes>
<include>**/*Test.*</include>
<include>**/*Suite.*</include>
</includes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>在src/main文件夹下新建文件夹scala,并且配置成源码目录,scala文件夹和java文件夹同级别。
spark官方样例代码
1
https://github.com/apache/spark/tree/master/examples/src/main/scala/org/apache/spark/examples
自己的wordCount程序
在项目根目录创建文件夹data/input,里面放一个word.txt文件作为基础数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29object WordCount {
def main(args: Array[String]): Unit = {
//todo 1.准备 sc/SparkContext/Spark 上下文执行环境
val conf: SparkConf = new SparkConf().setAppName("wc").setMaster("local[*]")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
//TODO 2.读文件
// RDD 弹性分布式数据集,简单理解为分布式集合,使用和普通集合一样。
// RDD[一行一行数据]
val fileRDD: RDD[String] = sc.textFile("data/input/words.txt")
//todo 3 数据操作转换
val words: RDD[String] = fileRDD.flatMap(_.split(" "))
val wordAndOnes: RDD[(String, Int)] = words.map((_, 1))
val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_ + _)
//todo 4.sink / 输出
result.foreach(println)
//收集为本地集合再输出
println(result.collect().toBuffer)
result.repartition(1).saveAsTextFile("data/output/a")
result.repartition(2).saveAsTextFile("data/output/b")
// 睡眠程序,去网页4040端口查看执行情况
Thread.sleep(1000*160)
sc.stop()
}
}执行过程4040端口查看

一个遇到的问题
(null) entry in command string: null chmod 0644
从网上下载一个hadoop.dll,扔到c:\windows\system32目录中即可。
2).打包yarn执行
遇到问题target\classes does not exist or is not a directory,错误原因:项目路径中含有中文。
修改一些写死的代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27object WordCount {
def main(args: Array[String]): Unit = {
if(args.length < 2 ){
println("请指定input和output文件夹")
System.exit(1) // 非0代表非正常退出
}
//todo 1.准备 sc/SparkContext/Spark 上下文执行环境
val conf: SparkConf = new SparkConf().setAppName("wc")
val sc = new SparkContext(conf)
sc.setLogLevel("WARN")
//TODO 2.读文件
// RDD 弹性分布式数据集,简单理解为分布式集合,使用和普通集合一样。
// RDD[一行一行数据]
val fileRDD: RDD[String] = sc.textFile(args(0))
//todo 3 数据操作转换
val words: RDD[String] = fileRDD.flatMap(_.split(" "))
val wordAndOnes: RDD[(String, Int)] = words.map((_, 1))
val result: RDD[(String, Int)] = wordAndOnes.reduceByKey(_ + _)
//todo 4.sink / 输出
//收集为本地集合再输出
result.repartition(1).saveAsTextFile(args(1))
sc.stop()
}
}执行package,进行打包
打包完成后,会生成两个jar,一个200M左右,里面有所有的依赖,一个只有10Kb大小,没有依赖,把没有依赖的jar包重命名为wc.jar,然后上传到/root目录下面。
提交执行任务
1
2
3
4
5
6
7
8SPARK_HOME=/opt/module/spark
{SPARK_HOME}/bin/spark-submit \
--master yarn \
--deploy-mode cluster \
--class live.shuoshuo.hello.WordCount \
/root/wc.jar \
hdfs://hadoop1:9000/wordcount/input/words.txt \
hdfs://hadoop1:9000/wordcount/output47_3 \