RDD详解 没有RDD/ Data Set之前做 Word Count(大数据计算)可以使用:
1.原生集合Java/ Scalar中的L山st但是只支持单机版!不支持分布式!如果要做分布式的计算需要做很多额外工作线程/进程通信,容错,自动均衡.…床烦,所以就诞生了框架
2.MR效率低运行效率低开发效率低)-早就淘汰
所以需要有一个分布式的数据抽象也就是用该抽象可以表示分布式的集合那么基于这个分布式集合进行操作就可以很方便的完成分布式的 Word Count!该分布式集合底层应该将实现的细节封装好提供简单易用的API!)
AMP实验室发表了一篇关于RDD的论文:《 Resilient Distributed Datasets: A Fault- Tolerant Abstraction forn- Memory Cluster Computing》就是为了解决这些问是题的–在此背景之下RDD就诞生了
1.RDD创建API 1.多种API
sc. parallelize(本地集合,分区数)
sc. makeRDD(本地集合,分区数)//底层使用的 parallelize
sc. textFile(本地/HDFS文件/文件夹,分区数)//注意不要用它读取大量小文件
sc. wholeTextFiles(本地/HDFS文件夹分区数)//专门用来读取小文件的
2.获取RDD分区数
rdd. getnumpartitions //获取rdd的分区数,底层是 partitions. length
rdd.partitions. length //获取rdd的分区数
2.分区操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 object RDDDemo01_Create def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setAppName("spark" ).setMaster("local[*]" ) val sc:SparkContext = new SparkContext (conf) sc.setLogLevel("WARN" ) val rdd1: RDD [Int ] = sc.parallelize(1 to 10 ) val rdd2: RDD [Int ] = sc.parallelize(1 to 10 , 3 ) val rdd3: RDD [Int ] = sc.makeRDD(1 to 10 , 3 ) val rdd4: RDD [Int ] = sc.makeRDD(1 to 10 , 3 ) val rdd5: RDD [String ] = sc.textFile("data/input/words.txt" ) val rdd6: RDD [String ] = sc.textFile("data/input/words.txt" , 3 ) val rdd7: RDD [String ] = sc.textFile("data/input/i/*" ) val rdd8: RDD [String ] = sc.textFile("data/input/i/*" , 3 ) val rdd9: RDD [(String , String )] = sc.wholeTextFiles("data/input/i/*" ) val rdd10: RDD [(String , String )] = sc.wholeTextFiles("data/input/i/*" , 3 ) println(rdd1.getNumPartitions) println(rdd2.getNumPartitions) println(rdd3.getNumPartitions) println(rdd4.getNumPartitions) println(rdd5.getNumPartitions) println(rdd6.getNumPartitions) println(rdd7.getNumPartitions) println(rdd8.getNumPartitions) println(rdd9.getNumPartitions) println(rdd10.getNumPartitions) } }
错误记录
使用sc.textFile("data/input/i")读取i文件夹下所有文件,出现错误:
解决方法:增加一个/*,sc.textFile("data/input/i/*")就可以
1 2 Exception in thread "main" java.lang.RuntimeException: Error while running command to get file permissions : java.io.IOException: (null ) entry in command string: null ls -F C:\xxxxxxxxxx\data\input\i\java_error_in_idea64_1552.log
3.RDD使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 object RDDDemo02_Basic def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setAppName("spark" ).setMaster("local[*]" ) val sc:SparkContext = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile("data/input/words.txt" ) val result: RDD [(String , Int )] = lines.filter(StringUtils .isNoneBlank(_)) .flatMap(_.split(" " )) .map((_, 1 )) .reduceByKey(_ + _) result.foreach(println) result.saveAsTextFile("data/output" ) } }
StringUtils类使用的是org.apache.commons.lang3.StringUtils包下的类。
优化上面代码,把map改成mapPartitions,把foreach改成foreachPartition
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 object RDDDemo02_Basic def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setAppName("spark" ).setMaster("local[*]" ) val sc:SparkContext = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile("data/input/words.txt" ) val result: RDD [(String , Int )] = lines.filter(StringUtils .isNoneBlank(_)) .flatMap(_.split(" " )) .mapPartitions(iter=>{ iter.map((_,1 )) }) .reduceByKey(_ + _) result.foreachPartition(iter=>{ iter.foreach(println) }) result.saveAsTextFile("data/output" ) } }
关于map和mapPartitions的区别
map:Return a new RDD by applying a function to all elements of this RDD.
通过将函数应用于此RDD的所有元素来返回新RDD。
mapPartitions:Return a new RDD by applying a function to each partition of this RDD.
通过对RDD的每个分区应用一个函数来返回一个新的RDD。
4.重分区函数/算子
增加/减少分区:repartion
减少分区:coalesce
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 object RDDDemo04_RePartition def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setAppName("spark" ).setMaster("local[*]" ) val sc:SparkContext = new SparkContext (conf) sc.setLogLevel("WARN" ) val rdd1: RDD [Int ] = sc.parallelize(1 to 10 ) val rdd2: RDD [Int ] = rdd1.repartition(9 ) val rdd3: RDD [Int ] = rdd1.repartition(7 ) println("rdd1 partition:" +rdd1.getNumPartitions) println("rdd2 partition:" +rdd2.getNumPartitions) println("rdd3 partition:" +rdd3.getNumPartitions) val rdd4: RDD [Int ] = rdd1.coalesce(9 ) val rdd5: RDD [Int ] = rdd1.coalesce(6 ) println("rdd4 partition:" +rdd4.getNumPartitions) println("rdd5 partition:" +rdd5.getNumPartitions) println("-------------------------------" ) } }
repartition底层是coalesce,如果需要使用coalesce进行增加分区,可在配置参数shuffle: Boolean = false,具体可以看代码。
5.聚合函数/算子 在数据分析领域,对数据聚合操作是最为关键的,在spark框架中各个模块使用是,主要就是其中的聚合函数的使用。
没有key的聚合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setAppName("spark" ).setMaster("local[*]" ) val sc:SparkContext = new SparkContext (conf) sc.setLogLevel("WARN" ) val rdd1: RDD [Int ] = sc.parallelize(1 to 10 ) val d: Double = rdd1.sum() println("sun结果:" +d) println(rdd1.reduce(_+_)) println(rdd1.aggregate(0 )(_ + _, _ + _)) }
有key的聚合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setAppName("spark" ).setMaster("local[*]" ) val sc:SparkContext = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile("data/input/words.txt" ) val wordAndOneRDD: RDD [(String , Int )] = lines.filter(StringUtils .isNoneBlank(_)) .flatMap(_.split(" " )) .map((_, 1 )) val grouped: RDD [(String , Iterable [Int ])] = wordAndOneRDD.groupByKey() val result: RDD [(String , Int )] = grouped.mapValues(_.sum) val result2: RDD [(String , Int )] = wordAndOneRDD.reduceByKey(_ + _) val result3: RDD [(String , Int )] = wordAndOneRDD.foldByKey(0 )(_ + _) val result4: RDD [(String , Int )] = wordAndOneRDD.aggregateByKey(0 )(_ + _, _ + _) result.foreach(println) println("-------------------------------" ) result2.foreach(println) println("-------------------------------" ) result3.foreach(println) println("-------------------------------" ) result4.foreach(println) }
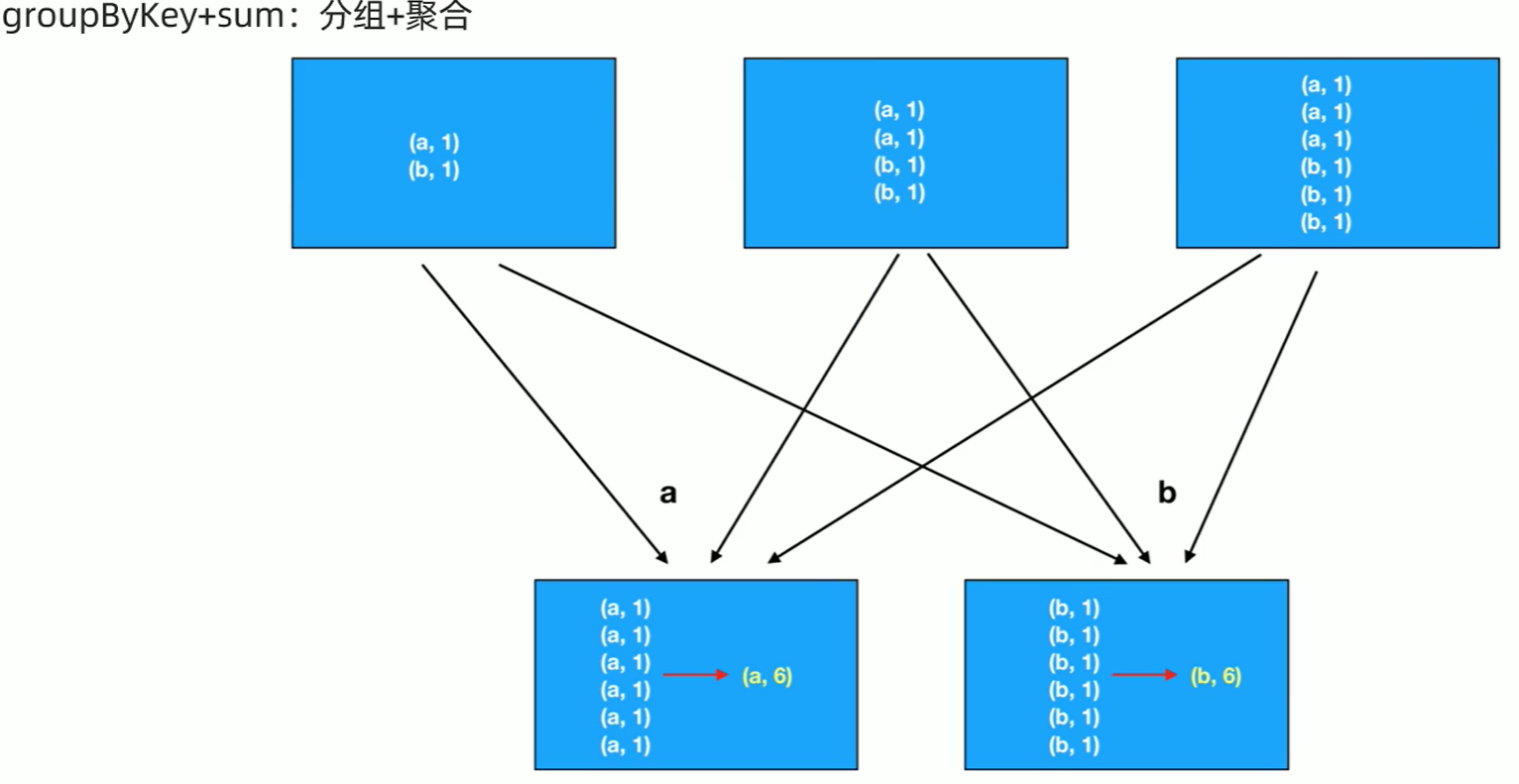
面试题:groupByKey和reduceByKet的区别 groupByKey是分组加聚合。
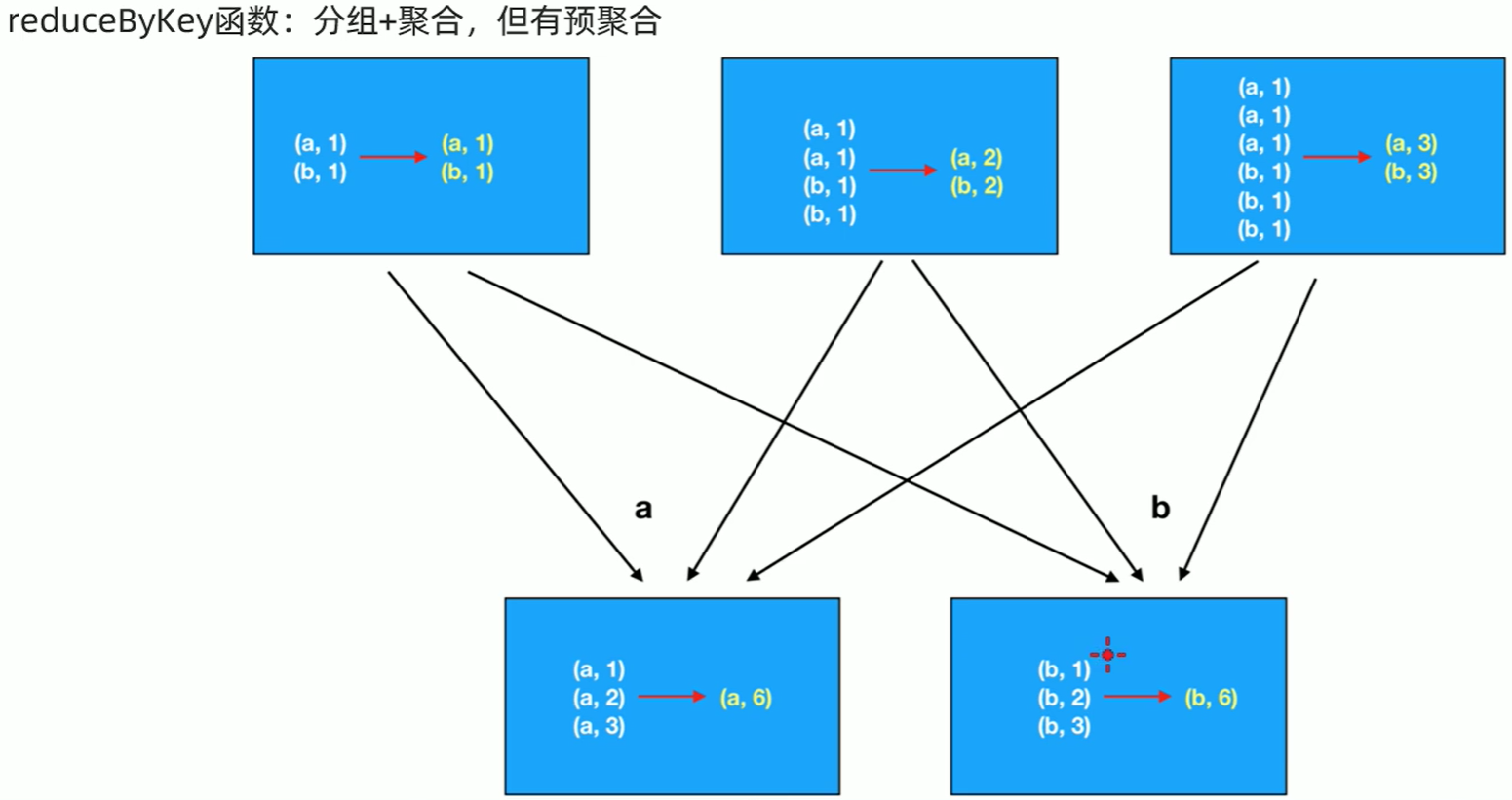
reduceByKey是预先聚合一下,再分组,再聚合,减少网络数据传输。
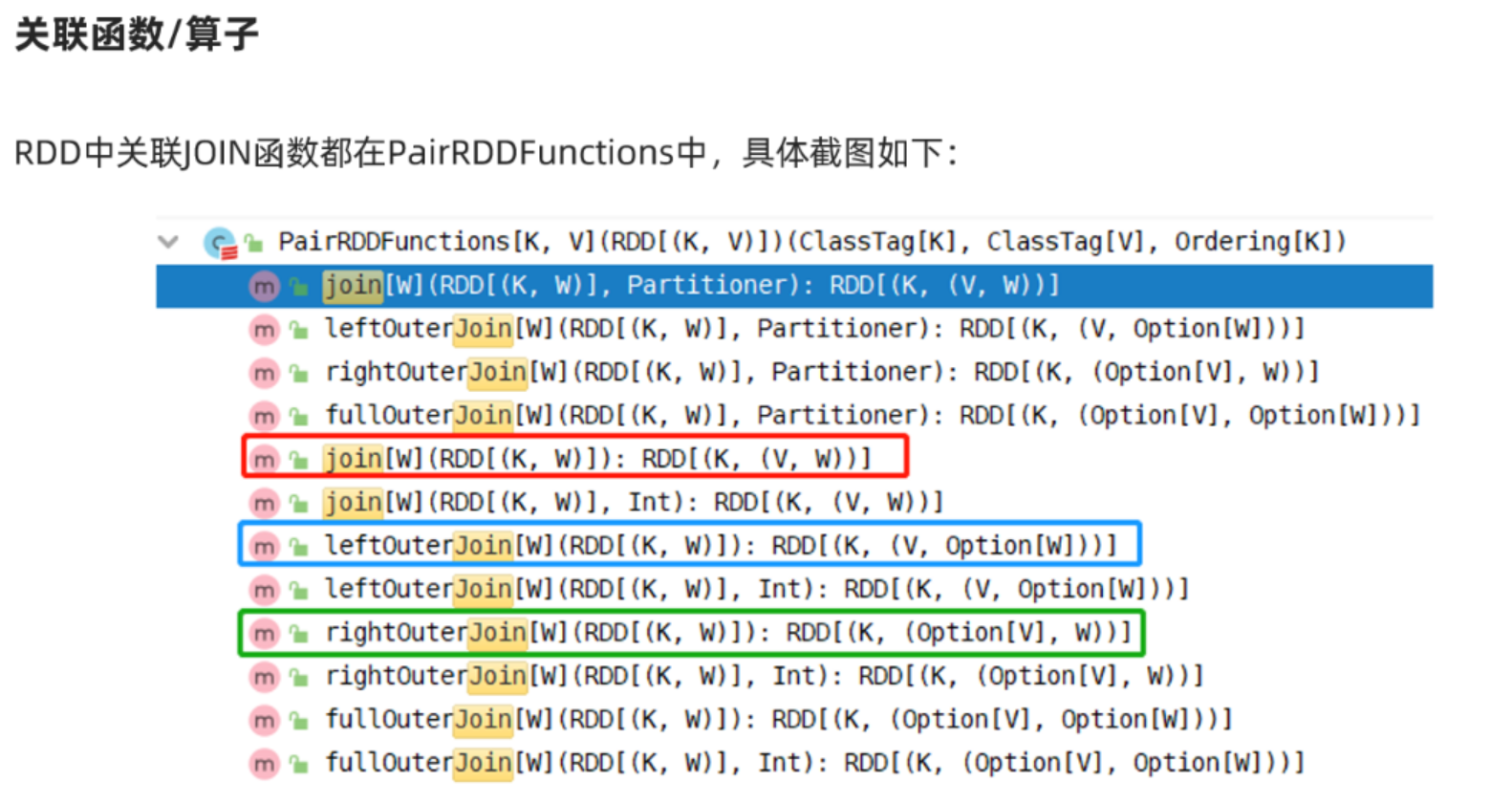
6.JOIN关联操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 package cn.itcast.coreimport org.apache.commons.lang3.StringUtils import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object RDDDemo07_Join def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setAppName("spark" ).setMaster("local[*]" ) val sc: SparkContext = new SparkContext (conf) sc.setLogLevel("WARN" ) val empRDD: RDD [(Int , String )] = sc.parallelize( Seq ((1001 , "zhangsan" ), (1002 , "lisi" ), (1003 , "wangwu" )) ) val deptRDD: RDD [(Int , String )] = sc.parallelize( Seq ((1001 , "销售部" ), (1002 , "技术部" ), (1004 , "客服部" )) ) val result1: RDD [(Int , (String , String ))] = empRDD.join(deptRDD) val result2: RDD [(Int , (String , Option [String ]))] = empRDD.leftOuterJoin(deptRDD) val result3: RDD [(Int , (Option [String ], String ))] = empRDD.rightOuterJoin(deptRDD) } }
三种join结果
1 2 3 4 5 6 7 1. 基础的join,只有左右两边都有才会保留这条数据,例如两个圆的重叠部分2. 以左边为基础,如果左边有,右边没有,则这个记录里面value为null ,例如1003 (1001 ,(zhangsan,Some (销售部))) (1001 ,(zhangsan,Some (客服部))) (1002 ,(lisi,Some (技术部))) (1003 ,(wangwu,None ))
7,.排序操作 排序操作一共有三种:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def main Array [String ]): Unit = { val conf: SparkConf = new SparkConf ().setAppName("spark" ).setMaster("local[*]" ) val sc:SparkContext = new SparkContext (conf) sc.setLogLevel("WARN" ) val lines: RDD [String ] = sc.textFile("data/input/words.txt" ) val result: RDD [(String , Int )] = lines.filter(StringUtils .isNoneBlank(_)) .flatMap(_.split(" " )) .map((_, 1 )) .reduceByKey(_ + _) val sortResult1: Array [(String , Int )] = result.sortBy(_._2, false ) .take(3 ) val sortResult2: Array [(Int , String )] = result.map(_.swap) .sortByKey(false ) .take(3 ) val sortResult3: Array [(String , Int )] = result.top(3 )(Ordering .by(_._2)) sortResult1.foreach(println) sortResult2.foreach(println) sortResult3.foreach(println) }